Update on Caplin and Roadmap: Building a Consensus Layer Client to work with Erigon without the Engine API.
This is an update on Caplin, Erigon's internal CL development progress and roadmap outlining.

In the Ethereum ecosystem, Erigon stands as an innovative client, excelling for archive nodes. In addition to Erigon, in the last few months, we announced Caplin, a consensus layer client that seamlessly integrates with Erigon, offering a direct approach to EL-CL interaction without relying on the Engine API. This innovation aims to improve user experience and performance. The post explores motivations, benefits, and the roadmap behind this initiative, along with implications for developers and users, contributing to Ethereum's growth. Importantly, while delving into the core aspects, it's important to note that the post will not delve into intricate technical details, ensuring accessibility and readability for a wide audience.
Motivation
Caplin was born out of the need to simplify the complex technical details that arose from "The Merge." Dealing with various client setups had become a headache, causing many issues. Additionally, changing the Engine API is a tough and time-consuming process. When new protocol concepts come in that require API changes, there's a long and strict validation process. This whole situation highlights the requirement for a smoother approach, which is what Caplin tries to achieve. As we explore this further, it's clear that Caplin's development journey aimed to make things more efficient and compatible in the evolving Ethereum environment.
Achievable Benefits
Caplin brings about advantages that can be divided into three main groups: Soft, Hard, and Protocol benefits. Soft benefits are the subtle perks that might not catch users' attention immediately. They include clearer code, easier codebase maintenance, and faster block import speeds. On the flip side, Hard benefits are more concrete and noticeable. They directly improve user experience, simplify infrastructure, make better use of data, and even have the potential to enhance Execution Layer (EL) pruning capabilities. These benefits are all quantifiable and enhance the overall usability.
Now, the Protocol benefits are the big-picture gains. These benefits extend beyond immediate user interactions and have a measurable impact on the Ethereum protocol as a whole. Caplin's design allows for introducing features that aren't available through the Engine API. This means protocol improvements can be made without needing all the other Consensus and Execution clients to agree. This approach accelerates protocol enhancements without getting stuck in prolonged consensus and approval processes. As Protocol benefits stack up, they enhance client performance, make the Ethereum ecosystem more adaptable and innovative, and introduce valuable optimizations.
Furthermore, an additional advantage lies in the potential to deliver an optimized Ethereum archive node (150GB< estimated) and beacon API (faster retrieval of data), which only Lighthouse and Nimbus are currently making an attempt at. However, it's worth noting that while this capability exists, it currently isn't a high priority due to limited demand for the beacon API, given its current structure. Designing a new API presents challenges and risks regarding effort and time investment. This pragmatic approach underscores the importance of aligning development efforts with tangible user needs and optimizing resource allocation for maximum impact.
Caplin Roadmap
Regarding the roadmap, Caplin's evolution is divided into four distinct phases, each signifying a critical milestone in its development and integration:
Phase 1: Engine API Integration In the initial phase, Caplin interfaces with the Engine API. This step enables Caplin to harness the comprehensive capabilities and functions provided by the Engine API. Notably, this integration also extends its utility to other Ethereum clients such as Geth, Besu, and Nethermind.
Phase 2: Internal Erigon API Integration Transitioning to the second phase, Caplin utilizes an internal Erigon API. This API is also crafted to integrate other chains other than Ethereum 2.0 (such as Polygon). Notably, this capability is a central point of the Caplin project.
Phase 3: Distributed Validator and Validation Client Progressing to the third phase, Caplin integrates the validator REST API capable of fulfilling the role of a proposing client.
Phase 4: Archive Node Capabilities Culminating in the fourth phase, Caplin extends its functionalities to include archive node capabilities.
Currently positioned in Phase 2 of development, our progress aligns with the integration milestone that involves utilizing the internal Erigon API. As we march forward, we anticipate making Caplin accessible to the public by the end of the year. This progressive step reflects our commitment to streamlining the operation of Erigon through Caplin's capabilities, serving as the default mode unless specifically indicated otherwise. Our strategic approach ensures the alignment of Erigon's functionality with Caplin's core principles and advancements, ultimately contributing to a more seamless and efficient Ethereum ecosystem.
Benchmarks
Below, we outline some Technical benchmarks which are subject to change as they are not that optimal yet but below are our results in block import time and Disk Footprint.
Disk Footprint
So, the disk footprint comprises 222 MB of indices and 16 GB of beacon blocks stored to serve the P2P RPC. There is still some room for improvement here in this regard, so this is not definite (it is quite a dumb approach so far). There is to note that the 16 GB worth of beacon blocks are stored as blobs, so one can choose to dump them on an HDD, thus practically reducing their cost to 0.
Block time importing
Below is the block importing time on a machine with an AMD Ryzen 9 5950X 16-Core Processor, which is a quite powerful but still affordable machine compared with Prysm:

Note: This is for block importing for Block processing in addition to ForkChoice computation. Additionally, Prysm and Caplin do different things; although they fully implement the consensus specs and fork choice rules, Prysm is a far bigger and more complete software. Above are just the rough numbers for raw optimistic (BLS verification only) block processing at the chain tip (so we exclude EL overhead).
Memory Consumption
Below are memory consumption benchmarks; I think that for non-validating nodes, this metric can very well be halved (also, this is out of a very dumb and unoptimized implementation of the forkchoice rule, just a more decent copy-cat of the consensus specification). I do not want to give definite answers here. It pretty much caps at 3.8 GB and never goes up, giving it a requirement of 4 GB of RAM to run Caplin.
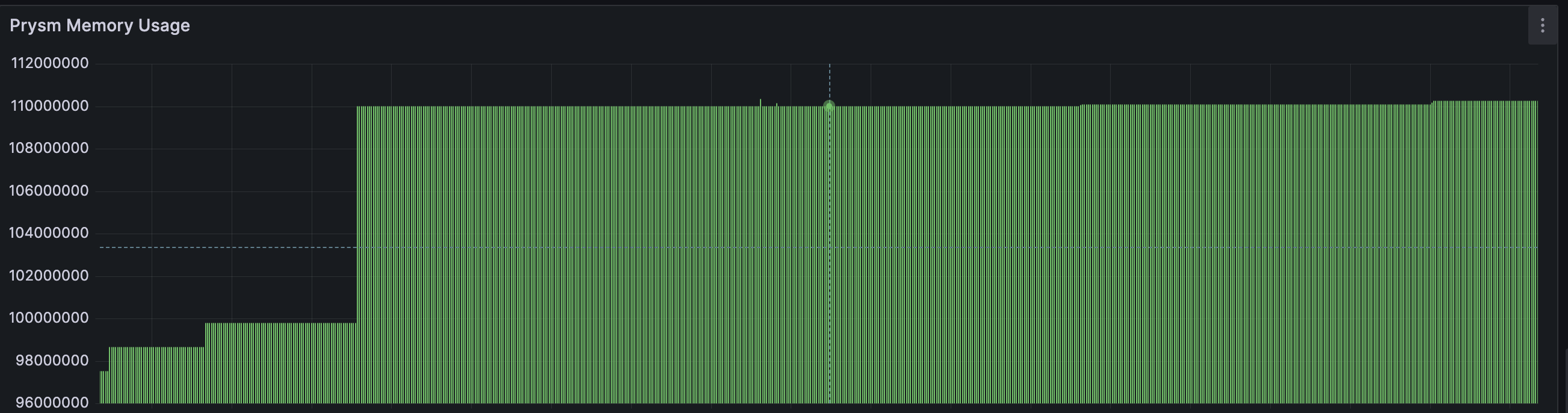
Below is Caplin's Memory usage compared to Prysm:
Prysm (approximately 11 GB):
Caplin (Approximately 4 GB):
