Staged Sync and short history of Silkworm project

In the beginning of 2020, a decision was made to introduce so-called Staged Sync to Erigon (back then, it was called “Turbo-Geth”). The idea is simple, but counter-intuitive.
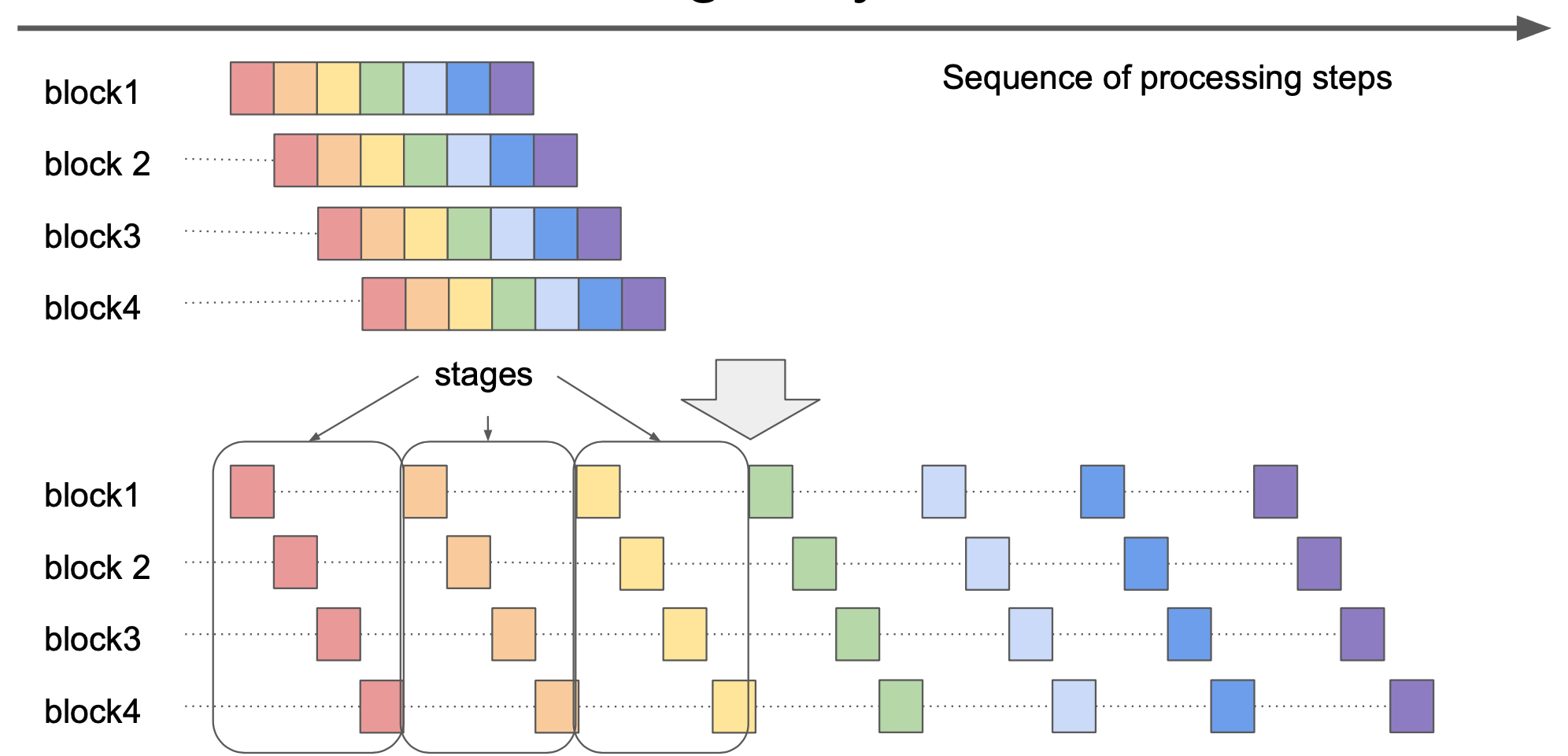
On the picture above, it is assumed that Ethereum implementation processes the blocks received from the network, as a series of pipelines. On the picture, there are 7 stages in such pipeline, shown by 7 colours (in reality, it does not have to be 7). Intuitively, one would want to maximise the utilisation of multi-core or multi-CPU computers and so run many pipelines concurrently. Staged sync goes against this intuition, and proposes the processing model where all available blocks first go through stage 1 of the pipeline, then all of them go through stage 2 of the pipeline and so on. Within each stage, concurrency is allowed, but more often than not, it is actually parallelism more than concurrency that matters. Certain stages in the pipeline, for example, verification of signatures are so-called “embarrassingly parallel” tasks. Others are mostly I/O bound and do not benefit from parallelism. In fact, concurrency may even degrade performance due to content switching and lost locality of data access.
The reason why Staged Sync looks counter-intuitive is that simple model shown in the picture above predicts that it will be slower than concurrent processing. In reality, it is not slower. It is not much faster either. As it was determined later, the main reason Erigon’s Staged Sync ends up being faster than alternatives, is the decoupling of state and Patricia Merkle tree in the data model. Using this decoupling, it is possible to defer the update of the Patricia Merkle tree, and computation of the state root until after all the EVM transaction processing is done, which speeds up the process significantly. Staged Sync makes this approach very natural and almost inevitable.
But other very interesting consequences of adopting the Staged Sync are to do with the development process of Erigon (and later Silkworm and Akula), so-called force multipliers:
Profiling of individual stage gives better insights about performance of that stage and results in quicker optimisations (force multiplier 1).
Well-defined inputs and outputs of each stage makes it possible to assemble and maintain them in isolation (force multiplier 2).
Significant speed up of the full sync (cut from couple of weeks to couple of days) enables more testing and empowers bigger changes (force multiplier 3).
The longest stage was (and still is) the replay of all transaction in EVM, and computation of the resulting state of Ethereum. This stage is customary called “Execution” stage. Due to the force multiplier mentioned above, a lot of profiling and optimisations have been performed in the beginning on 2020, and eventually we arrived at this rough split of wall time:
Roughly 1/3 was taken by the EVM interpreter
Roughly 1/3 was taken by the Golang’s garbage collector (after optimisations targeting allocations)
Roughly 1/3 was taken by I/O (mostly reads from LMDB - this was prior to MDBX)
At the same time, we saw experiments of evmone’s team (evmone is EVM interpreter written in C/C++) to integrate into go-ethereum. We integrated evmone (via EVMC interface) into Erigon (then Turbo-Geth). Even though the sheer performance of evmone was better than built-in interpreter inherited from go-ethereum, there was a lot of overhead introduced by the EVMC interface coupled with CGo (Golang’s interface for interacting with the code written in other languages). The main problem was that EVMC is designed around not just calling of the “host” into EVMC, but also calling out of EVMC into the “host”. And the latter part was introducing the overhead. In order to fix this, we needed to effectively “enlarge” EVMC to envelope it with some extra C/C++ code to remove the interfacing overheads.
We also determined that squeezing more out of Golang in terms of minimising allocation would lead to poorer readability of code and deviation from the idiomatic use of the language. We thought: instead of writing in Go as if it was C++, we might as well just write in C++.
And this is how the Silkworm project (C++ implementation of Ethereum based on Erigon component model, data model, and Staged sync architecture) started. This happened around May 2020.
The current status of Silkworm project will be described in one of the future posts.