Releasing Caplin's Archival format.
Update on Caplin

We're thrilled to announce the release of the Caplin Archival format. The Caplin Archival format represents a significant milestone designed to improve access efficiency and ensure greater integrity for beacon blockchain data. This enhancement promises to significantly reduce input/output (I/O) operations, deliver better latency, enable more efficient data processing and reduce operational costs across the board.
Issue with historical data on the Beacon chain.
Modern historical data management on the Ethereum beacon chain has encountered several challenges, making operations cumbersome and inefficient for archival nodes. These challenges primarily revolve around high input/output (I/O) operations, latency, and the sheer volume and complexity of the data, with disk sizes for archival nodes often exceeding 4 terabytes (TB). Let's delve into these issues to understand their impact:
High I/O Operations: Archival nodes store a complete history of all states and blocks on the Ethereum network. This requires frequent reading and writing operations to the disk, leading to high I/O throughput. The intensive I/O demands can slow down the performance of archival nodes, especially when processing or validating new transactions and blocks. This is because the system's ability to read from and write to the disk efficiently is a critical factor in overall performance. When these operations become a bottleneck, it directly impacts the speed and efficiency of the network.
Latency: The latency in accessing data from disk storage is significantly higher than accessing the same data from memory (RAM). As archival nodes deal with vast amounts of data, they rely heavily on disk storage. This reliance results in increased latency when accessing historical data, which can slow down query responses and data processing.
Disk Sizes Exceeding 4 TB: The Ethereum blockchain continuously grows, adding new blocks approximately every 12 seconds. This constant growth leads to an exponential increase in the data that archival nodes must store. Modern archive nodes often see their disk sizes exceed 4 TB, which increases hardware costs and complicates data management and retrieval. Large disk sizes mean that more data must be scanned for each query, which can further increase latency and I/O operations, exacerbating the existing challenges.
Right now, the two main (that we know of) contenders are trying to fix this problem:
Lighthouse’s experimental tree states data model.
Caplin’s data model.
Therefore, to give a better picture of it. We will present some benchmarks by putting them against one another, comparing the memory consumption of the two nodes under stress, latency of retrieved data, and disk size.
Disk Footprint: Lighthouse Tree-States VS Caplin.
First of all, Lighthouse Tree-states and Caplin have similar archival sizes (up to 8.4 Million slots)

.
Caplin is a little smaller, with 145 GB of additional disk footprint required, while Lighthouse stands at 180 GB. They are roughly the same in terms of sync speed and database population speed. The main difference between the two, when it comes to the data model, is that Lighthouse tree-states keep track of what essentially is a diff-tree of each instance of the state throughout history using xdelta3 (a delta-compression algorithm), while Caplin uses internal indexing and pre-loading to keep track of the changes as opposed to the tree-states approach. This leads to a slightly smaller disk footprint. However, this difference in approach also leads to faster data processing and extraction times. So, how do they differ in application latency?
Latency: Lighthouse Tree-States VS Caplin.
To measure latency, we decided to compare the timings on the Restfull API from both Beacon nodes. We selected three endpoints to test, which we believe to touch all the spots regarding data processing. The first and most important for reorg handling is how fast each client can read a previous state. We benchmarked the /eth/v2/debug/beacon/states/{state_id} in octet-stream to do this. Below are the results:

We can see that caplin sits all the time below the one-second mark while lighthouse-tree states go as far as to exceed 2 seconds at times. Making Caplin approximately 2x times faster at reading historical states.
We also ran two other benchmarks on how fast historical individual (or even multiple) validator data and rewards are retrieved. Below are the results for retrieving individual validator data.

We can see that Caplin is six times faster at retrieving this kind of data by showing a slow growth curve over time, while Lighthouse seems to pick up latency as we approach the most recent slot data. Lastly, a measurement for validators deltas tracking is shown:
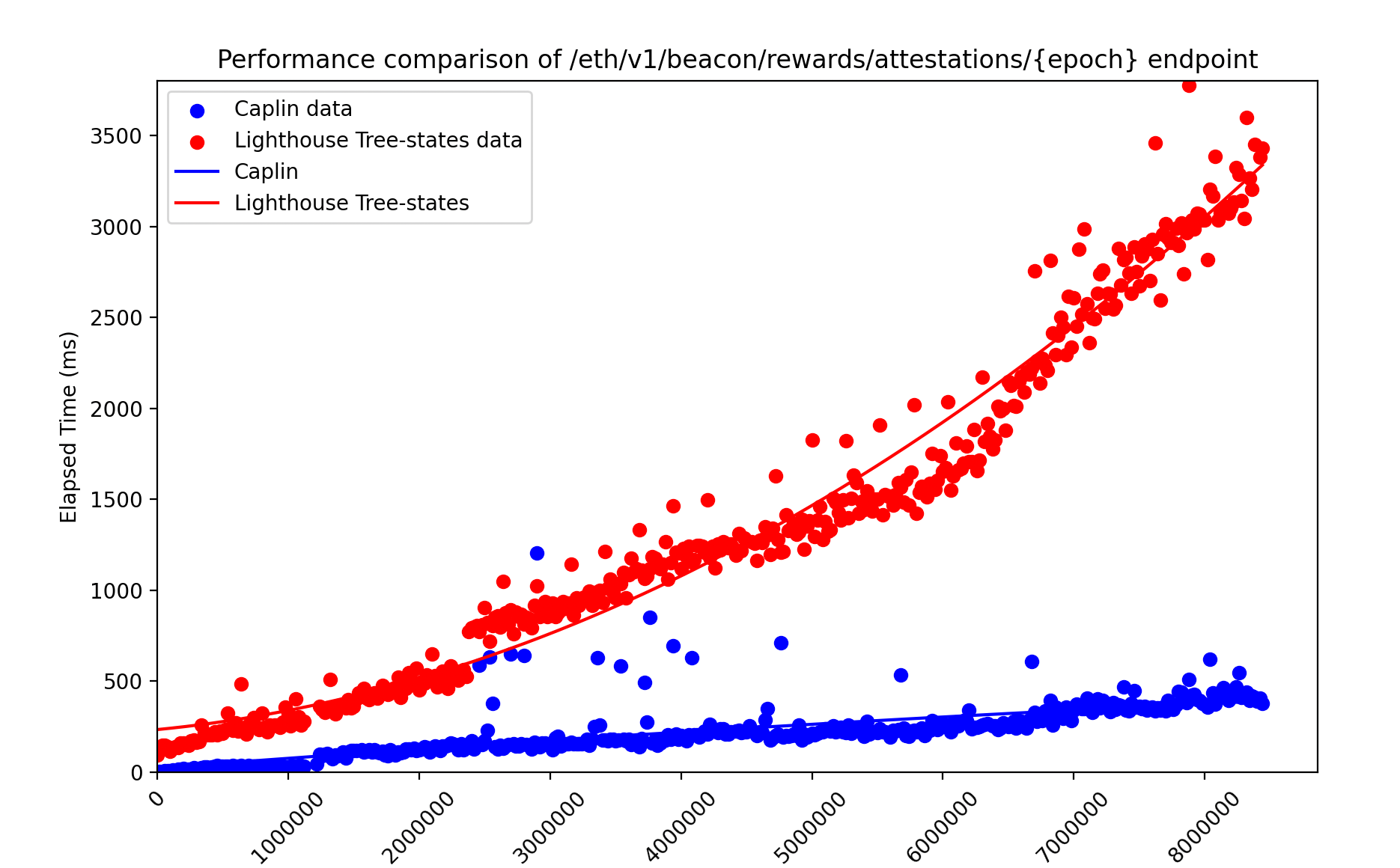
We also picked this endpoint to test computation and processing on pre-existing beacon data. The results show that Caplin is ten times faster than a lighthouse regarding historical data processing.
Network improvements
To add a final note: in the past two weeks, the Caplin team finally fixed the recurring issue of Caplin occasionally missing a few gossip blocks. The issue was that we completely messed up the size of a P2P Message. Luckily, that does not happen anymore, and other functionalities, such as being a Validator, are in reach.
What’s next?
From the next release, Caplin’s archive node will be able to be enabled using the flags —-internalcl and —-caplin.archive, these two flags will enable backfilling and reconstruction of states. The next step is to implement the full-validator functionality and work on bug fixing and improving current things. The Caplin team also starts researching efficient means of blob retrieval and storage for Layer 2s.